
그룹이 아닌 계층으로서의 Go 패키지
이번 포스팅은 지난번 어떠한 방식으로 Go코드를 구조화해야 하는가? 포스팅과 마찬가지로 Go 소스 코드의 구조화에 대한 고민의 연장선입니다.
이번에 번역해 본 글도 지난번 포스팅과 동일한 저자가 작성한 글이며 Go 소스 코드의 구조화에 관련된 글을 4년이 지난 후에 다시 한번 게시해주셨더라고요. Go 어플리케이션을 제작할 때 패키지들 간의 관계를 어떻게 바라볼 것인가에 대해 한 번 더 고민할 수 있는 시간이었습니다.
원문을 참고하실 분들은 해당 링크를 확인해주시기 바랍니다.
목차
그룹이 아닌 계층으로서의 Go 패키지
숙련된 Go 개발자들에게도 가장 어려운 주제중 하나인 package layout에 대해 다루어보고자 4년전에 Standard Package Layout이라는 글을 게시했었습니다. 하지만 대부분의 Go 개발자들은 여전히 그들의 어플리케이션과 함께 방대해져갈 소스 코드를 디렉토리 구조로 정리하는것에 대해 어려움을 겪고 있습니다.
Four years ago, I wrote an article called Standard Package Layout that tried to address one of the most difficult topics for even advanced Go developers: package layout. However, most developers still struggle with organizing their code into a directory structure that will grow gracefully with their application.
거의 모든 프로그래밍 언어는 관련된 기능들을 함께 그룹화하는 메커니즘을 갖고 있습니다. Ruby는 gems, Java는 pacakages를 갖고 있습니다. 이러한 언어들은 코드를 그룹화 하는 일반적인 규약을 갖고 있지 않는데 솔직히 이것이 크게 중요하지 않기때문입니다. 코드를 그룹화하는 것은 전적으로 개인의 취향에 달려있습니다.
Nearly all programming languages have a mechanism for grouping related functionality together. Ruby has gems, Java has packages. Those languages don’t have a standard convention for grouping code because, honestly, it doesn’t matter. It all comes down to personal preference.
하지만 Go언어로 전환하는 개발자들은 매우 빈번하게 그들의 패키지 구조화가 그들을 다시 괴롭히게 된다는 것에 놀라게 됩니다. Go의 패키지는 다른 언어의 패키지의 개념과 왜 이렇게 다른걸까요? 그것은 바로 Go에서 패키지 개념은 그룹이 아닌 계층이기 때문입니다.
However, developers that transition to Go are surprised by how often their package organization comes back to bite them. Why are Go packages so different from other languages? It’s because they’re not groups—they’re layers.
순환 참조 이해하기
Go 언어의 패키지와 다른 언어들에서의 그룹화간의 주요한 차이는 Go 언어에서는 패키지간의 순환 의존을 허용하지 않는다는 것에 있습니다. 패키지 A가 패키지 B에 의존할 수 있지만 이와 동시에 패키지 B가 패키지 A에 의존적일 수는 없습니다.
The primary difference between Go packages and grouping in other languages is that Go doesn’t allow for circular dependencies. Package A can depend on package B, but then package B cannot depend back on package A.
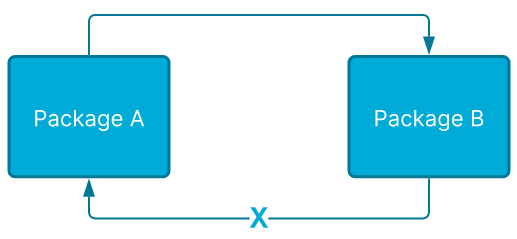 Package dependencies can only go one way
Package dependencies can only go one way이러한 제약은 나중에 개발자들이 A와 B 패키지 모두에서 공통된 코드를 공유하게 하고자 할 때 문제를 야기하게 합니다. 이러한 문제에 대한 2가지 정도의 솔루션이 있습니다. 두 패키지를 단일 패키지로 합치거나 또 다른 세번째 패키지를 도입하는 것입니다.
This restriction causes issues for developers later on when they need to have both packages share common code. There are typically two solutions: either combine both packages into a single package or introduce a third package.

하지만 더 많은 패키지들로 분할해가는 것은 문제를 더 키우는 꼴입니다. 결국엔 실제 구조가 존재하지 않는 거대한 패키지들의 집합으로 귀결될 것입니다.
However, splitting out into more and more packages only pushes the problem down the road. Eventually, you end up with a large mess of packages and no real structure.
스탠다드 라이브러리 차용하기
Go 프로그래밍 시에 활용되는 가장 유용한 팁들 중에 하나는 여러분이 가이드가 필요할 때는 Go의 기본 라이브러리를 참고하라는 것입니다. 이 세상에 완벽한 코드라는 것은 없지만 Go의 기본 라이브러리는 해당 언어를 설계한 사람들이 이상적이라고 생각하는 내용들을 압축하고 있습니다.
One of the most useful tips when programming Go is to look to the standard library when you need guidance. No code is perfect, but the Go standard library encapsulates many of the ideals of the creators of the language.
예를 들어, net/http 패키지는 아래 그림과 같이 net 패키지의 추상을 기반으로 만들어지며 net 패키지는 io 레이어의 추상을 기반으로 만들어집니다. net 패키지가 net/http 패키지에 의존적일 수 있다고 가정하는 것은 다소 무의미하기 때문에 이러한 패키지 구조는 꽤 잘 동작합니다.
For example, the net/http package builds on top of the abstractions of the net package, which, in turn, builds on the abstractions of the io layer below it. This package structure works well because it would be nonsensical to imagine the net package needing to somehow depend on net/http.

Go의 기본 라이브러리에서 잘 동작하는 것과는 별개로 이것을 Go 어플리케이션 개발에 적용하는 것은 어려울 수 있습니다.
While this works well in the standard library but can be difficult to translate to application development.
어플리케이션 개발에 계층 개념 적용하기
WTF Dial이라는 어플리케이션을 예로 들어 살펴볼 예정이므로 이 어플리케이션에 대해 좀 더 살펴보고자 하시는 분들은 해당 포스팅을 읽어 보시면 됩니다.
We’ll be looking at an example application called WTF Dial, so you can read the introductory post to understand more about it.
이 어플리케이션은 2개의 논리적 계층을 가지고 있습니다:
In this application, we have two logical layers:
- An SQLite database
- An HTTP server
우리는 sqlite와 http 패키지를 각각 생성합니다. 많은 사람들이 Go의 기본 라이브러리 패키지와 동일한 형태의 패키지 이름을 사용하는 것을 꺼려할 것 입니다. 이러한 우려는 유효한 지적이고 여러분은 http 대신에 wtfhttp라고 네이밍할 수도 있을겁니다. 하지만 우리의 HTTP 패키지는 net/http 패키지를 완전히 캡슐화하기 때문에 동일한 파일 내에서 우리의 HTTP 패키지와 net/http 패키지를 함께 사용하는 경우는 결코 발생하지 않습니다. 저는 모든 패키지 이름에 접두어를 붙이는 작업은 지루하고 보기싫다라고 생각하기 때문에 그 짓은 하지 않겠습니다.
We create a package for each of these — sqlite & http. Many people will balk at naming a package the same name as a standard library package. That’s a valid criticism and you could name it wtfhttp instead, however, our HTTP package fully encapsulates the net/http package so we never use them both in the same file. I find that prefixing every package is tedious and ugly, so I don’t do it.
단순한 접근
우리의 어플리케이션을 구조화하는 한가지 방법은 데이터 타입(User나 Dial과 같은)과 함수(FindUser()나 CreateDial()과 같은)를 sqlite 패키지에 포함시키는 것입니다. http 패키지는 sqlite 패키지에 직접적으로 의존할 수 있습니다:
One way to structure our application would be to have our data types (e.g., User, Dial) and our functionality (e.g., FindUser(), CreateDial()) inside sqlite. Our http package could depend directly on it:

이것은 그리 나쁜 접근 방식이 아니며 단순한 어플리케이션에서는 꽤 잘 동작합니다. 하지만 몇가지 문제들에 직면하게 될겁니다. 첫째로 데이터 타입은 sqlite.User와 sqlite.Dial로 네이밍되는데 데이터 타입이라는 것은 SQLite가 아니라 우리 어플리케이션에 속하는 것이므로 이러한 네이밍은 좀 이상해보입니다.
This is not a bad approach, and it works for simple applications. We end up with a few issues though. First, our data types are named sqlite.User and sqlite.Dial. That sounds odd as our data types belong to our application—not SQLite.
둘째로 위 구조상 HTTP 계층에서는 오로지 SQLite에 대한 데이터만을 제공할 수 있습니다. 만약 이 두 계층 사이에 캐싱 계층을 하나 추가한다고 하면 어떤일이 벌어질까요? 또 SQLite가 아닌 PostgreSQL 혹은 디스크에 존재하는 JSON 형식의 데이터와 같은 다른 형태의 타입들은 어떻게 지원할까요?
Second, our HTTP layer can only serve data from SQLite now. What happens if we need to add a caching layer in between? Or how do we support other types of data storage such as Postgres or even storing as JSON on disk?
마지막으로 SQLite를 추상화하는 계층이 존재하지 않기때문에 모든 HTTP 테스트에서 SQLite 데이터베이스를 구동해야만 합니다.
Finally, we need to run an SQLite database for every HTTP test since there’s no abstraction layer to mock it out. I generally support doing end-to-end testing as much as you can, but there are valid use cases for introducing unit tests in your higher layers. This is especially true once you introduce cloud services that you wouldn’t want to run on every test invocation.
비즈니스 도메인 고립시키기
우리가 변경할 수 있는 첫번째 사항은 비즈니스 도메인을 그들 자체적인 패키지로 이동시키는 것입니다. 이러한 도메인을 “어플리케이션 도메인”이라고 칭할 수도 있습니다. 이것은 여러분의 어플리케이션에 특화된 데이터 타입입니다.
The first thing we can change is moving our business domain to its own package. This can also be called the “application domain”. It’s the data types specific to your application—e.g., User, Dial in the case of WTF Dial.
저는 이러한 목적으로 root 패키지(wtf)를 사용하는데, 이는 이미 제 어플리케이션 이름에 따라 편리하게 네이밍되어있고, 새로운 개발자가 코드 베이스를 열어 볼 때 가장 먼저 보는 곳이기 때문입니다. 이제 데이터 타입의 이름은 wtf.User, wtf.Dial로 위에서 나온 이름보다는 더 적절해 보입니다.
I use the root package (wtf) for this purpose as it’s already conveniently named after my application, and it’s the first place new developers look when they open the code base. Our types are now named more appropriately as wtf.User and wtf.Dial.

여러분은 아래 예시에서 wtf.Dial 타입을 볼 수 있습니다:
You can see an example of this with the wtf.Dial type:
- go
1 | type Dial struct { |
위 코드에서는 세부 구현에 대한 어떠한 참조도 존재하지 않습니다. 단지 Go의 내장 타입들과 time.Time만 존재합니다. JOSN 태그는 편의를 위해 추가했습니다.
In this code, there is no reference to any implementation details—just primitive types & time.Time. JSON tags are added for convenience.
추상화 서비스를 통한 의존성 제거
어플리케이션의 구조가 조금은 더 나아진것 같아 보이지만 HTTP가 SQLite에 의존적이라는 것은 여전히 어색합니다. 우리의 HTTP 서버는 데이터 저장 공간이 SQLite인지 아닌지는 신경쓰지 않고 데이터를 전달하기를 원합니다.
Our application structure is looking better, but it’s still odd that HTTP depends on SQLite. Our HTTP server wants to fetch data from an underlying data storage—it doesn’t specifically care if it’s SQLite or not.
이 부분을 수정하기 위해, 비즈니스 도메인 내에 서비스들을 제공하기 위한 인터페이스를 생성할겁니다. 이 서비스들은 전형적인 CRUD 이지만 또 다른 동작을 수행하도록 확장할 수도 있습니다.
To fix this, we’ll create interfaces for the services in our business domain. These services are typically Create/Read/Update/Delete (CRUD) but can extend to other operations.
- go
1 | // DialService represents a service for managing dials. |
이제 우리의 도메인 패키지(wtf)는 데이터 구조뿐만 아니라 계층 간의 커뮤니케이션 방식을 정의한 인터페이스도 구체화되었습니다. 이것은 우리의 패키지 계층 구조를 수평적으로 만들어주었으며 이를 통해 이제 모든 패키지들은 도메인 패키지에 의존하게됩니다. 이것은 패키지간의 직접적인 의존 관계를 깰 수 있도록 해주며 mock 패키지와 같은 부가적인 구현들도 추가할 수 있게 해줍니다.
Now our domain package (wtf) specifies not just the data structures but also the interface contracts for how our layers can communicate with one another. This flattens our package hierarchy so that all packages now depend on the domain package. This lets us break direct dependencies between packages and introduce alternate implementations such as a mock package.

패키지의 재패키지화
패키지간의 의존성을 깨는것은 우리가 작성한 코드를 유연하게 사용할 수 있도록 해줍니다. 우리의 어플리케이션 바이너리인 wtfd에 대해선 여전히 http 패키지가 sqlite에 의존적이지만 테스트를 위해 http 패키지가 새로운 mock 패키지에 의존하도록 변경할 수 있습니다.
Breaking the dependency between packages allows us flexibility in how we use our code. For our application binary, wtfd, we still want http to depend on sqlite (see wtf/main.go) but for our tests we can change http to depend on our new mock package (see http/server_test.go):

이것은 WTF Dial과 같은 작은 웹 어플리케이션에서는 조금 지나친 작업일 수 있으나 우리가 소스 코드를 늘려 나감에 있어서는 점차 중요한 문제가 될 겁니다.
This may be overkill for our small web application, WTF Dial, but it becomes increasingly important as we grow our codebase.
결론
패키지는 Go 언어에서 매우 강력한 도구입니다. 하지만 여러분이 패키지를 계층이 아닌 그룹으로 바라본다면 끝없는 혼란의 원천이기도 합니다. 여러분이 만든 어플리케이션의 논리적인 계층을 이해한 후에 데이터 타입과 비즈니스 도메인을 위한 인터페이스를 추출해낼 수 있으며 이것들을 나머지 모든 서브 패키지들이 참조할 수 있도록 하는 범용적인 도메인 언어를 제공하기 위한 루트 패키지로 옮길 수 있습니다. 도메인 언어를 정의하는 것은 시간이 지남에 따라 여러분의 어플리케이션 규모를 키워나가는데 필수적입니다.
Packages are a powerful tool in Go but are the source of endless frustration if you view them as groups instead of layers. After understanding the logical layers of your application, you can extract data types & interface contracts for your business domain and move them into your root package to serve as a common domain language for all subpackages. Defining this domain language is essential to growing your application over time.
해당 게시글에서 발생한 오탈자나 잘못된 내용에 대한 정정 댓글 격하게 환영합니다😎
reference